どうも、スマコマのコマ太郎です。![]()
今回は検索エンジン対策(SEO)初心者のために検索エンジンの仕組みについて解説してみようと思います。(初心者と書いてますが、まだちょっと難しいかも。でも図があるので多少理解できるはず!)
ここでは検索エンジン対策そのものは扱いませんが、SEO周りの記事を読むときに知っておきたい用語、仕組みについて解説しています。
例えば、以下のような用語に関して少しでも疑問があるようなら、きっと役立つ内容のはずです。
- クローラー、スパイダー、ボット?
- インデックス、インデクサ?
- アルゴリズム、検索アルゴリズム?
- 検索クエリ?
なお、一応 Google をベースに説明しますが、Bing などの他の検索エンジンも同じです。
検索エンジンの仕組み
検索エンジンを使えば、一瞬で世界中のウェブページの中からあなたが必要とするページを探すことができます。
でもなぜこんなに高速に検索結果を弾き返すことができるのでしょうか?
その秘密は検索エンジン システムの仕組みにあります。中にはホームページを作れば、勝手に人が見に来てくれると思っている人もいますが、実際には検索エンジン システムが収集したデータだけを検索対象にしているのです。
ではまず、こちらの図をご覧ください。
検索エンジンシステムの全体図
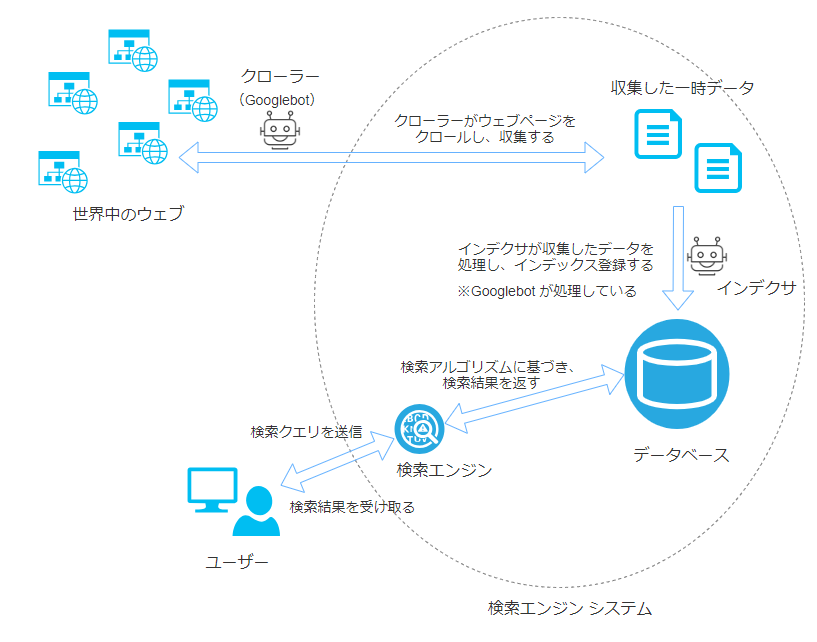
これが検索エンジン システムの全体像です。検索エンジン システムは主に以下のような3つのフェーズで構成されています。
フェーズ1(左上):ページの発見
フェーズ2(右上):データベースへの登録(インデックス登録)
フェーズ3(下):検索結果を返す
SEO記事でよく見かけるクローラーとは、ページを発見するプログラムのことで、ウェブ(クモの巣)のリンクをたどって新しいページを探すことからスパイダーと呼ばれることや単にボット(ロボットの略)と呼ばれることもあります。
ページの発見(クローラーとクロール)
このフェーズでは検索エンジンはクローラーを使って、新しいページの発見、更新されたページの発見、データの収集を行います。これをクロールする(crawl)と言います。
クロールと言えば、水泳を思い出しますが、意味は「もぞもぞ動く」です。スパイダーがもぞもぞ動く様から来ているものと思われます。
このクローラーのもっとも基本となる役割はリンクをたどって新しいウェブページを発見すること、更新されたページを発見することです。ただこのプロセスだけではウェブページの発見が遅れるため、クローラーにクロールを通知する方法が用意されています。
それがXMLサイトマップです。XMLサイトマップにはウェブサイトのURLリスト、更新日時、更新頻度、優先順位などのデータが格納でき、それを用意することでクローラーを呼び込む助けになります。下図はXMLサイトマップの例です。
XMLサイトマップの例

クローラーはサイトに訪れた際、まず最初に robots.txtファイルを探し、XMLサイトマップがあればそれを参考にクロールを行ってくれるのです。下図は robots.txtファイルの例です。このように robots.txtファイルに XMLファイルの所在を記述し、クローラーに知らせることができます。
robots.txtファイルの中身

ただ、どうせXMLサイトマップを用意するなら、Google Search Console に XMLサイトマップは登録しておきたいですね。Search Console に XMLサイトマップを登録しておくことでページの発見プロセスをすっ飛ばしてくれます。(実際にクローラーが来るかどうかは、それを処理するアルゴリズムによりますが)
https://smakoma.com/google-xml-sitemaps.html
また Search Console を使えば、ページ単位でクロールをリクエストすることも可能です。

インデックス登録(インデクサとインデックス)
次のフェーズはクローラーが収集したデータを解析して、データベースに登録する処理です。この処理プログラムのことをインデクサと言い、言語が分解され、検索アルゴリズムが効率的に検索できるように中間処理されインデックスが作成されます。
インデックスとは、本でいう索引のことであり、索引があることで検索エンジンは高速に処理することができるようになります。ちなみにインデックスはデータベース用語です。
あとさらっと流したインデクサ(indexer)は、このインデックス(index)を作成するプログラムであるからインデクサと言います。この用語はあまり見かけないので、さらっと流して問題ないと思いますが、古い記事で見かけます。
ちなみに Googlebot は、クローラーとインデクサの両方の役割を担っています。ページを発見、収取し、さらにインデックス登録もしているということですね。
検索結果を返す(クエリとレスポンス)
最後のフェーズは、検索クエリに対して結果を返すことです。クエリ(query)とは、問い合わせる(検索エンジンに問い合わせる)ことであり、検索クエリはユーザーが入力したキーワードを指します。
この検索クエリを元に、検索エンジンは検索結果を返しているのです。(レスポンス)
このとき検索順位を決定する処理ルールを検索アルゴリズムと言い、検索エンジン周りでアルゴリズムのアップデートと言えば、通常はこの検索アルゴリズムの変更のことを言っています。
ちなみにアルゴリズムとは処理手順(ルール)のことであり、クローラーがクロールして情報を処理する挙動も、インデクサがデータをインデックス登録する際の処理もアルゴリズムが介在します。(それぞれクローラー アルゴリズム、インデクサ アルゴリズムと言います)
この説明は帰って混乱させてしまうかもしれませんが、アルゴリズムとは処理手順のことであり一般名称であるという点に注意してください。
どの部分のアルゴリズムかという視点を持つと、より深く理解できるようになると思いますよ。
まとめ
初心者向けに書いたつもりが言いたいことを書いていったら結局難しくなってしまいました。
しばらく加筆修正を繰り返して、よりよいものにしてみたいと思います。
もし分かりにくい点、もっと知りたいところがあれば、コメント欄からお知らせくださいね。
ではでは!








