どうも、スマコマのコマ太郎です。![]()
グーグルのサーチコンソールのカバレッジを見ていて気付いたのですが、「クロール済み – インデックス未登録」として feed ページが大量に検出されていました。
この「クロール済み – インデックス未登録」というのは、グーグルのロボットがページを読み込みはしたのだけど、まだグーグルのインデックス(データベース)には登録してないよ。または価値がないと判断したので登録しなかったよという意味になります。
検索エンジン システムのプロセス図で説明すると、以下の赤矢印が指し示す位置の状態(ステータス)です。
検索エンジン システムのプロセス図
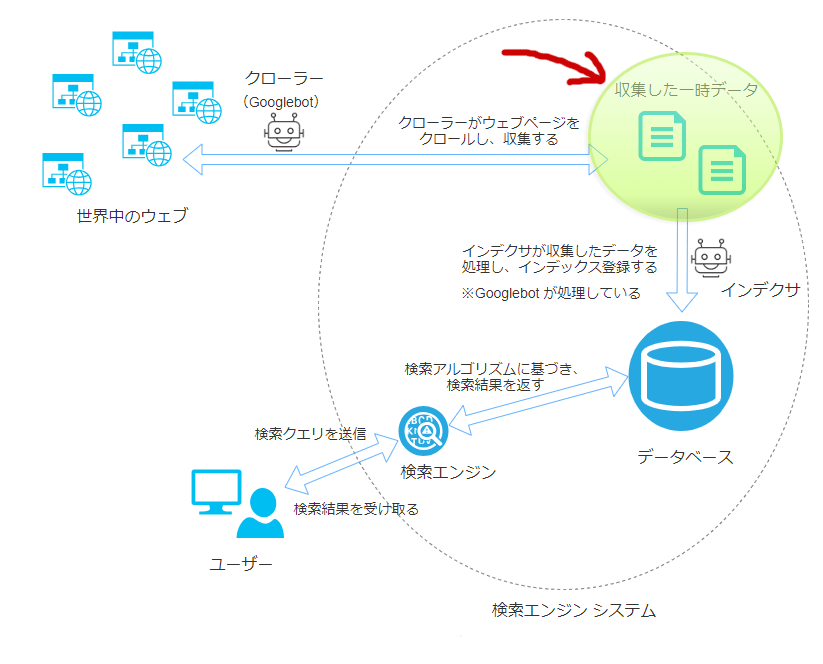
なお後者の価値がないと判断されたページをSEO界隈では低品質なページなどと呼びますが、低品質なページが多くあるとサイトの評価が落ちてしまうのです。
なので「クロール済み – インデックス未登録」はゼロが望ましいわけです。でも feedページだし、まあいいかと思っていたのですが、あまりに数が増えてきて、本当に低品質になっているかもしれないページが埋もれて見つけにくい状態になってきました。
なので、ちょいと設定をいじってみました。その備忘録として記事を起こしています。
もくじ
feedページの状態をサーチコンソールで確認
まずどんな状態だったのかですが、サーチコンソールでカバレッジを開きます。
サーチコンソール カバレッジ画面

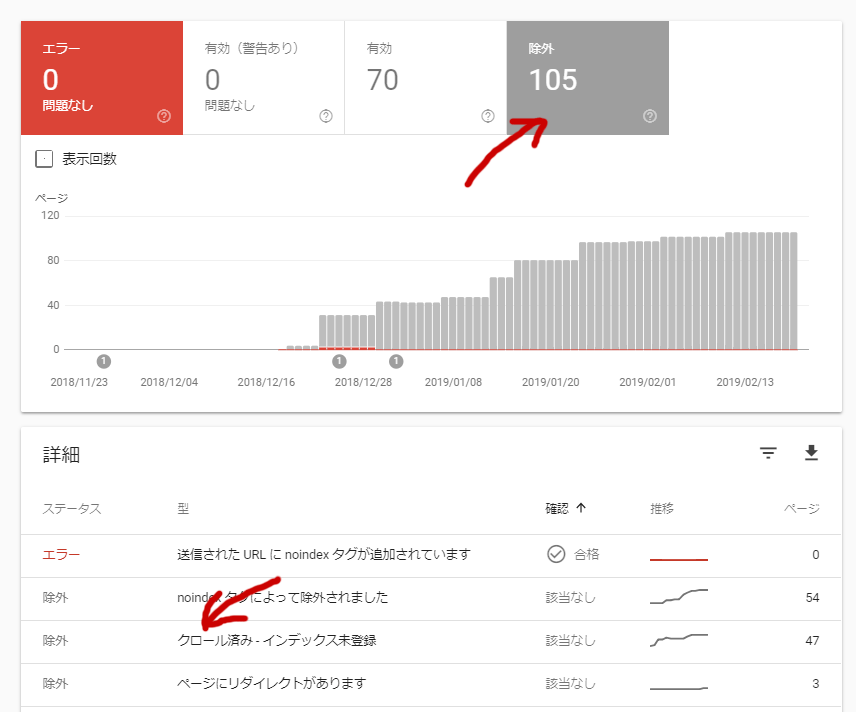
その中にある「クロール済み – インデックス未登録」で 47件が未登録になっていました。
クロール済み – インデックス未登録
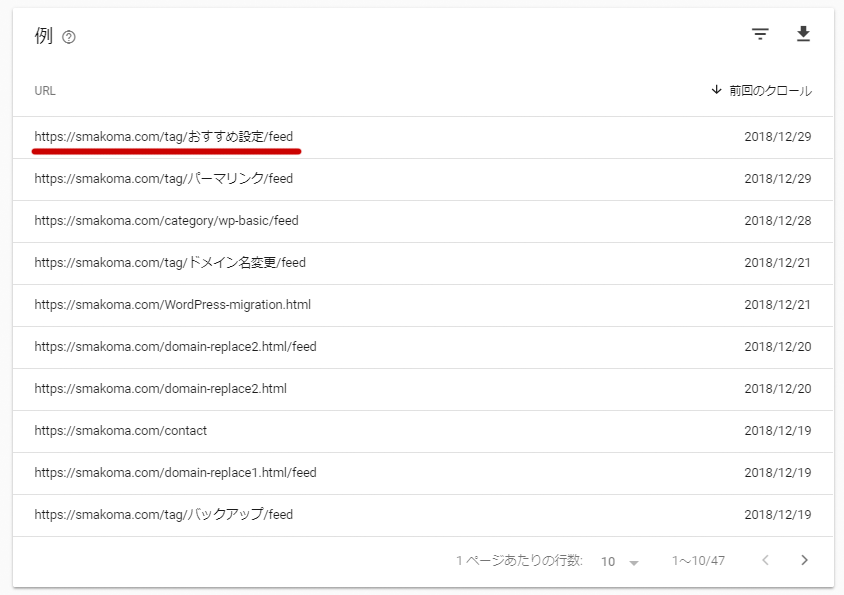
さらに詳細を確認すると、このように URLの最後が feed となっているページが大量に検出されていたのです。
この各ページにぶら下がる feedページは、WordPress の機能の1つでコメント欄をオープンにすると自動的に生成されるページです。この feed をグーグルに読み込ませる必要はないので、これを除外したいわけです。
feedページを noindex にする方法
対策1:プラグインで対処する
feedページは HTML形式のページではないので、metaタグで noindex することができません。feedのようなXML形式のファイルの場合、HTTPヘッダーの X-Robots-Tag を使って除外する必要があります。
で、その方法ですが、「All In One SEO Pack」か「Yoast SEO」というプラグインを使うことで可能になります。(使っているテーマにSEO機能が搭載されていると競合するので注意してください。TCDなど。)
これらのプラグインは使っている人も多いと思いますが、このプラグインをインストールし有効化すれば自動的(※追記参照)にfeedページの HTTPヘッダーに X-Robots-Tag: noindex, follow が追加されます。特に追加の設定などは必要ありませんでした。
「All In One SEO Pack」のデフォルト設定が version 4.0.17 以降、変更されており手動で設定を調整する必要があります。
設定手順
1. [All In One SEO Pack]-[検索の外観] をクリックする。
2. [高度な設定]タブをクリックする
3. [グローバルロボットメタ] の [デフォルト設定を使用]ボタンをオフにする
4. [No Index RSS Feeds]チェックボックスをオンにして、[変更を保存] をクリックする。
参考)Setting Noindex for RSS Feeds (AIOSEO Documentation)
HTTPヘッダー
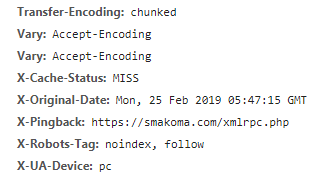
このようにHTTPヘッダーに X-Robots-Tag が追加されていることが確認できました。HTTPヘッダーは、Google Chrome で簡単に確認することができます。

ただ解せないのが、そもそもこのプラグインは入っていたこと。なのでプラグインにバグがあったのか、グーグル側の挙動に問題があったのか分かりません。(追記:2019/06/26 思い出したのですが、初期に使っていたテーマは TCD の MAXX でした。TCD には、SEO機能が組み込まれているので、All In One SEO Pack を入れてませんでした。しかもソースを見るとfeedの記述があって、これをたどられたみたいですね)
一応、「クロール済み – インデックス未登録」の状態についてグーグルのヘルプを確認すると以下のように書かれています。
クロール済み – インデックス未登録: ページは Google によりクロールされましたが、インデックスには登録されていません。今後、インデックスに登録される可能性がありますが、登録されない可能性もあります。この URL のクロールのリクエストを再送信する必要はありません。(インデックス カバレッジ レポートより)
一時的に入る可能性はありそうですね・・・(追記:2019/03/07 グーグルのインデックスも有限で限界が近づいてきたので、仕訳の精度が厳しくなってきているという話を聞きました。)
後述した操作でサーチコンソールを確認するとステータスが [インデックス登録を許可] が [はい] から [いいえ] になったことから、あとはグーグル側の処理待ちですね。
対策2:functions.php に処理をフックするコードを記述する
クローラーを制御するのは、「All In One SEO Pack」や「Yoast SEO」プラグインを使うのが簡単ですが、何かの事情で使えない、使いたくないということもあるかと思います。
その場合は、functions.php に以下のコードを追加することで、処理をフックし feedページに X-Robots-Tag を追加することもできます。
|
1 2 3 4 5 |
add_action( 'template_redirect', function() { if ( is_feed() && headers_sent() === false ) { header( 'X-Robots-Tag: noindex, follow', true ); } } ); |
functions.php にコードを追記する場所ですが、お使いのテンプレート(テーマ)によって差異がありますので、ご使用のテンプレートのマニュアルも確認してください。
なおコードを追加する際は、functions.php をバックアップしてから操作することをおすすめします。
対策3:robots.txt でブロックする
余計なプラグインを追加することは避けたいし、コードを追加することも避けたい。
そのときは、robots.txt に以下を追加するという方法もあります。
User-Agent: *
Disallow: /feed$
Disallow: /*/feed$
旧サーチコンソールの robots.txt テスターでクローラーをブロックできることは確認済みです。
ただ、これはクロールの拒否であり、インデックスの拒否ではないのでクロール済みのものに対し、どのような挙動になるか分かりません。今後のページに対してのみ有効と考えた方が良さそうです。
参考:.htaccess で制御できないか?
.htaccess を使って制御できないかについても検討しました。.htaccess で「Header set X-Robots-Tag “noindex”」をセットすることで、HTTPヘッダーに X-Robots-Tag を追加することができます。
ですが、「feed」に対してパターンマッチさせることができませんでした。おそらく、拡張子のない「feed」を、Apache がファイルとして識別しないことが原因で、<Files>ディレクティブが機能しないのでしょう。
サーチコンソールで確認する方法(プラグインで対処した場合のみ)
ではグーグル側からどのように見えているかも確認しておきましょう。
グーグルサーチコンソールの [カバレッジ] の中にある [除外]パネルをクリックし、さらに[クロール済み – インデックス未登録]をクリックします。
カバレッジ画面
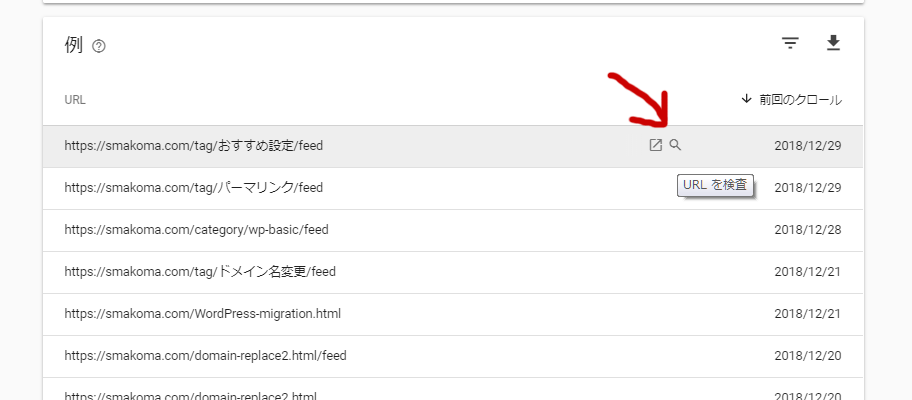
目的の URL にマウスカーソルを当てると虫眼鏡アイコン(URL検査)が出てくるので、それをクリックします。
URL検査
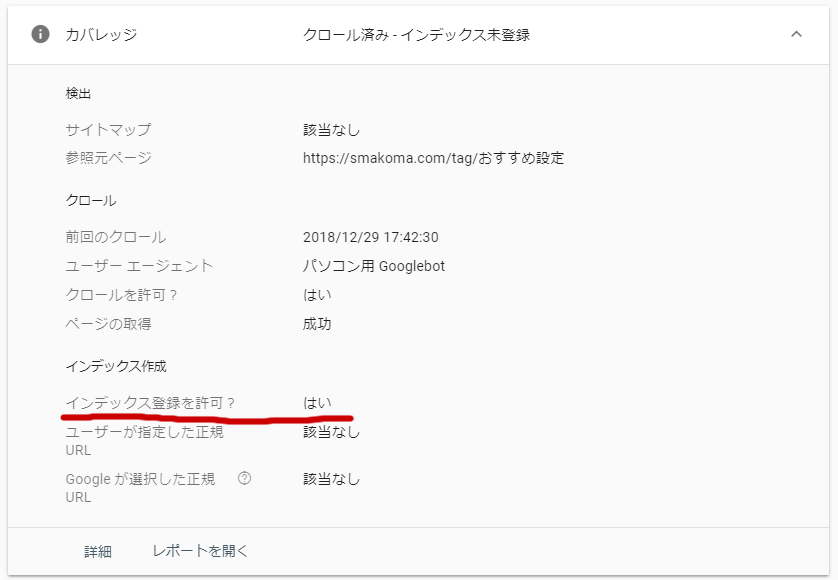
次の画面でインデックスの状態を確認することができます。
インデックス状態を確認
この画面の右上にある [公開URLを検査] をクリックしてみてください。
インデックス状態 その2

設定が反映されていれば、インデックス許可が「いいえ」になるはずです。
あとは放置しておくだけ。そのうち feedページ群は [noindex タグによって除外されました] に移動してくれるでしょう。
追記:2019/06/26 結局、移動が始まるのにfeedページのクロール日から見た日数で半年かかりました。。。除外されたページにクローラーを呼ぶ機能がサーチコンソールにないので仕方ありませんね。手書きでxmlサイトマップを作って、クローラーを呼び込むことも考えましたが、移動が始まったので放置しました。














いつも参考にさせていただいています!今回私もサチコでfeedページが大量に除外されたのでYoast SEOを入れてみたのですが、GoogleXML Sitemapと合わなくて、さらにfeedページもうまくノットインデックスにならず、どん詰まりです。他に良い方法はないでしょうか…
こんにちは。
Yoast SEO はテスト環境に入れて、feedページに noindex が追加されることを確認しています。なぜnoindexにならないかは分かりませんが環境依存の問題でしょう。
もしかしてキャッシュプラグインなど入っていませんか? キャッシュプラグインが入っているとページが更新されないとファイルが新しくならないので追加されないように見えるかもしれません。
またはブラウザのキャッシュの問題かもしれません。noindexを確認する際、スーパーリロードはお試しいただけましたか?
https://smakoma.com/browser-super-reload.html
ほかの方法としてはページ内で提示しているrobots.txt を使う方法もありますよ。
ちなみに feedページが大量に出てしまうのは気持ち悪いので、ぼくも対処しましたが、SEO上は放置して何ら問題ないはずです。世界で利用されているWordPressの仕様をグーグルが無視するとは考えにくいですからね。そこは慌てず対処すればいいでしょう。
返信が遅れて申し訳ありません!
なるほど、スーパーリロードでもう一度試してみます!
そう、なんだか気持ちわるので消したくて消したくて(/ _ ; )焦らず諦めずにチャレンジしてみます!ありがとうございます!
コマ太郎様
ブログを立ち上げたばかりの初心者です。
検索していてURLの最後に/feedがあるのに気が付きました。 サチコのカバレッジのサーバーエラーは立ち上げ当初にメンテナンスモードにしていたのに、チェックをわすれて、クロールされた事が原因だと思います。その後、すぐに外したのですが、5XXのエラーのまま、どう対処したらよいかと思っていました。
テーマはswellを使っていて、開発者の方の作った推奨のSEO SIMPLE PACKを使用しています。
申し訳ありませんが、初心者でもわかるようにご指導いただけますか?
こんにちは。
>その後、すぐに外したのですが、5XXのエラーのまま、どう対処したらよいかと思っていました。
この5xxエラーが表示されているのは、サチコのカバレッジということでしょうか?
—
Google側の挙動ですが、なくなったページ(feedページを非表示にした場合)はクロールできないので修正を確認することができません。
確認できないので保留となり、そのまま長期間(半年くらい)残ることになります。ですが最後には消えますので、放置すればいいですよ。
コマ太郎様、コメントありがとうございます。
>この5xxエラーが表示されているのは、サチコのカバレッジということでしょうか
そうです。
また、feedページを非表示にする対処方法ですが、コマ太郎さんの上記、記述ではプラグインか、functions.phpコードを追記かと思うのですが、プラグインは使用しているテーマ(swell)推奨のSEO Simple packを入れていて、All In One SEO Packは不具合報告が出ており、推奨されていない様なので、入れるのが不安です。
また、正直、functions.phpコードを追記するにあたって、エディターは警告が出て、躊躇してしまいました。
Yoast SEOを入れてみようかと思いますが、今入れている推奨のSEO Simple packと入れ替えるという事でよろしいでしょうか。
こんにちは。
テーマ推奨のプラグインがあるなら、販売者のサポートを考えるとそちらを使うのがよろしいかと思います。
>また、正直、functions.phpコードを追記するにあたって、エディターは警告が出て、躊躇してしまいました。
初めてテーマエディターを起動するときに警告メッセージが出ますね。
安易に操作するべきではありませんがバックアップと復元さえできるなら、別に怖がる必要もないです。
逆にバックアップと復元ができないなら、やらないほうがいいでしょう。
コマ太郎様
経験と思って、準備を整えた後、挑戦したいと思います。ご指導ありがとうございました。